Abstract: 关于GAN的一种形式pix2pix的简介
paper:Image-to-Image Translation with Conditional Adversarial Networks
code: https://github.com/phillipi/pix2pix
简介
该工作出自UC Berkeley的BAIR实验室,主要是将Conditional GAN广泛应用于各种图图转换(Image-to-Image Translation)。所谓图图转换,就是给定一张原始图片,然后基于此图片生成目标图片,其中目标图片与原始图片在某些内容或者说语义上具有一致性。下图列举了部分相关的任务。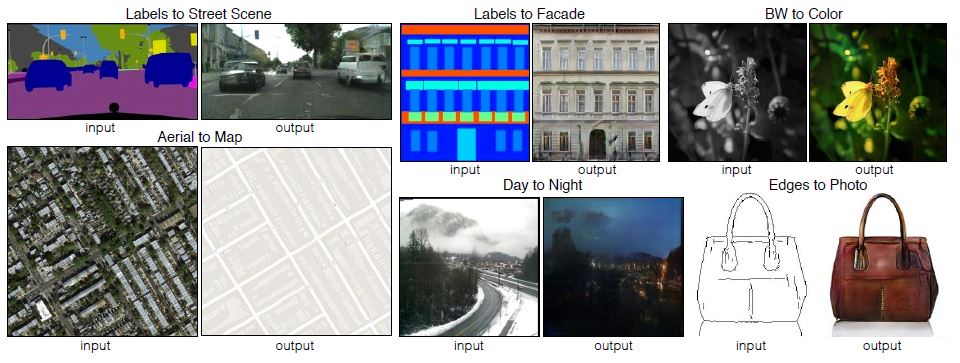
方法
pix2pix本质上是一个Conditional GAN。不一样的是,pix2pix将通常的Conditional GAN中需要人为控制的信息编码向量用输入的原始图片替换,对应的模型基本示意如下图。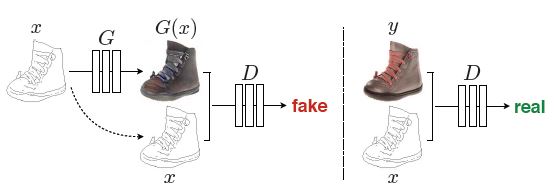
目标函数
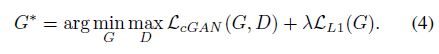
其中,
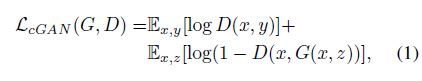
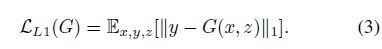
损失函数分为两部分,第一部分是Conditional GAN对应的adversarial loss,第二部分是约束生成图片接近ground truth的L1 loss,之所以使用L1 loss而非L2 loss,是因为使用L2 loss会使得生成的图片结果偏模糊。
网络结构
- Generator:U-net,对于编码器和解码器的镜像对应部分采用跨层连接(skip connections),避免原本输入和输入图片都包含的低层次信息在编码到bottleneck的过程中丢失。
- Discriminator:convolutional PatchGAN,作者argue说对输入输出单纯使用L1或者L2 loss会使得生成的图片结果偏模糊,为了使得生成的图片清晰(或者说包含较丰富的高频信息),以NxN大小的patch作为Discriminator的输入,将图片中所有patch判别结果的均值作为Discriminator最后的判别输出。在patch level进行处理的Discriminator有效地将图片建模为MRF(Markov random field),假设间距超过patch范围的像素间相互独立,PatchGAN可以被视为是某种形式的纹理/风格损失(texture/style loss)。
特点
作者号称“noting is application-specific”。本方法无须根据具体应用专门设计loss,通过PatchGAN,与具体任务相关的loss是自学习得到的,与单纯计算像素误差的L1/L2 loss相比,学到的是structured loss,如前面所说PatchGAN等效于做了一个MRF的建模假设。实验结果
