Abstract: 机器学习基石(林轩田)第二讲,介绍感知机(Perceptron)内容。
感知机的假设(hyperplanes in $\mathbb{R}^d$):

$$perceptrons \Leftrightarrow linear(binary)classifiers$$
从假设空间H中找出真实关系f的近似g。
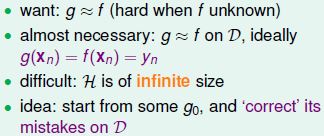
Perceptron Learning Algorithm (PLA)
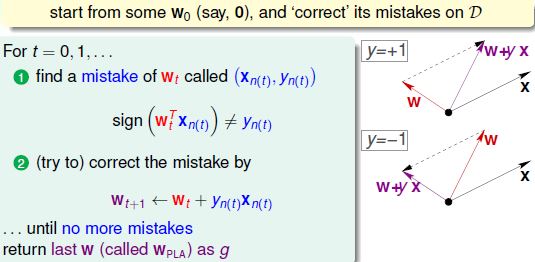
当y=+1的样例被错判时,w与x内积为负,夹角太大,需要往小的方向纠正,反之亦然。
具体实现
通过依序循环查找直至完全没有错例为止。
算法的停止条件:线性可分

其中,使用$w_f^T w_t$表示当前学到的权重w与真实值的相近程度。
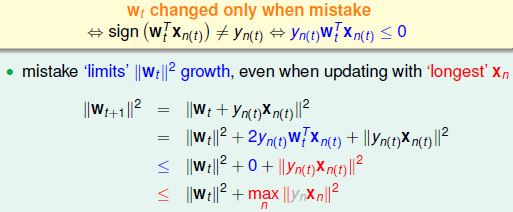
假设从$w_0=0$开始,经过T轮的错误矫正:
$$
\begin{align}
\frac{w_f^T w_T}{||w_f|| ||w_T||} &\geq \frac{w_f^T w_0+T\min\limits_{n}y_nw_f^Tx_n}{||w_f|| ||w_T||}\\
&\geq \frac{w_f^T w_0+T\min\limits_{n}y_nw_f^Tx_n}{||w_f||\sqrt{||w_0||^2+T\max\limits_{n}||x_n||^2}}\\
\xrightarrow{w_0=0} &\geq \sqrt{T} \frac{\min\limits_{n}y_nw_f^Tx_n/||w_f||}{\max\limits_{n}||x_n||} \\
\xrightarrow[R^2=\max\limits_{n}||x_n||^2]{\rho=\min\limits_{n}y_n\frac{w_f^T}{||w_f||}x_n} &\geq \sqrt{T}\frac{\rho}{R}
\end{align}
$$
因为$\frac{w_f^T w_T}{||w_f|| ||w_T||}$的最大值为1,因此在线性可分的情况下,PLA修正次数满足:
$$
T \leq \frac{R^2}{\rho^2}
$$
实际上,我们可以知道R大小,但是w_f却是未知的,因此实际需要的修正次数T边界也未知。如果迭代一段时间后仍未停止,我们无法判断是未完成(线性可分)或者根本就是线性不可分的。
考虑噪声存在(Pocket Algorithm)
实际采集到的数据总是有噪声的干扰,所以有可能会线性不可分,可以尝试找到:
$$
w_g \leftarrow \mathop{\arg\min}_{w}\sum_{n=1}^{N}I[y_n \neq sign(w^Tx_n)]
$$
其中,$I[·]$为指示函数,内容为真时取1,为假时取0。
该问题已被证实为NP难。Pocket Algorithm
modify PLA algorithm (black lines) by keeping best weights in pocket
基本思想是对比修改前后的错误样例,若修改后错误变少,则执行修改,有贪心算法的意思。
该算法相比PLA,缺点是速度慢,每次更新前都要统计错误样例数并进行对比。