Abstract: 介绍与图像翻译相关的三篇论文:CoGAN(NIPS2016)、CycleGAN和DualGAN(ICCV2016)。三者的共同点在于,不要求训练数据是成对匹配的(paired)不同域(domain)的图像,可以直接针对两个没有匹配标注的不同域图像集合直接进行训练。
CoGAN: Coupled GAN
paper: Coupled Generative Adversarial Networks
code: https://github.com/mingyuliutw/cogan
作者在文中声称:- “It can learn a joint distribution with just samples drawn from the marginal distributions.”
- “This is achieved by enforcing a weight-sharing constraint that limits the network capacity and favors a joint distribution solution over a product of marginal distributions one.”
也就是说,最原本的想法是需要学习两个域的联合分布,图像翻译相当于给定其中一个域的值,此时对应的另一个域的值的变化遵从一定的概率分布,找出其中概率较大的一个值作为翻译的结果(可以考虑噪声的影响)。因为实际的数据没有配对标注,因此训练的样本分别从两个域的集合中(实质上对应的就是边缘分布)选取。
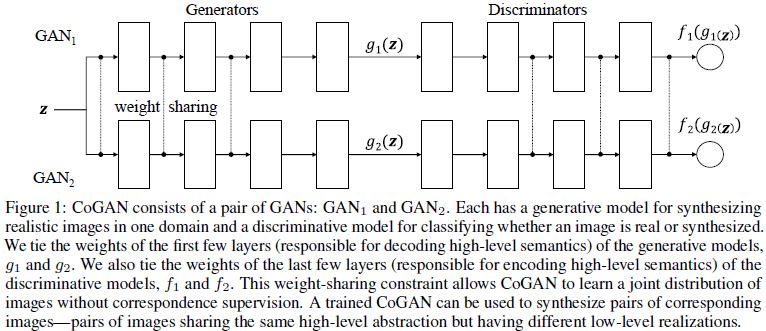
假定两个图像的域在较为抽象的语义层次上具有相似性或一致性,通过共享GAN中生成器和判别器网络的高层次(对应低分辨率)的layers参数,可以在结构上施加这个约束,从而限制网络的capacity。使用两个GAN的做法,可以视为将原来的联合分布的学习近似为为两个边缘分布的乘积。- 通过共享参数的方法,可以在没有配对数据的情况下学习到联合分布。
- 尽管实验证明判别器是否共享参数基本不影响结果(这隐式地说明判别器共享参数不是学习两个域的联合分布的关键),但是可以减少参数。
- 域之间需要有一致的高层次表示,这是使用CoGAN的前提。
CoGAN的结构示意图如下:
目标函数就是两个GAN的目标函数之和:
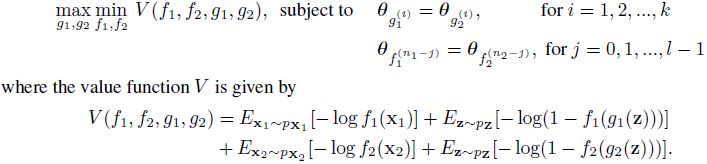
在人脸属性上的一个示例:

CycleGAN:
paper: Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
homepage: https://junyanz.github.io/CycleGAN/
作者借用了自然语言翻译里面的一个想法,即一句英文通过英-法翻译得到对应的法语表达,再通过法-英翻译得到的英语表达意思要与最初的英文一致。因此,为了实现unpaired数据的学习,作者构造了两个域相互转换的生成器以及对平的判别器,并提出了所谓cycle-consistency的概念。
损失函数
Adversarial Loss:(但是具体实现中为保证稳定性和生成图片的清晰度,作者采用least-square loss)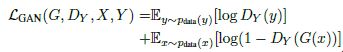
Cycle Consistency Loss:(不使用L2 loss是为了减小生成图像的模糊程度)
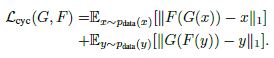
整体的目标函数:
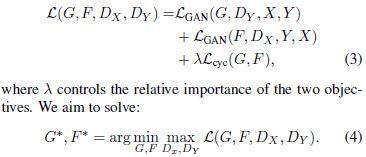
一个例子:将普通马转化为斑马

DualGAN:
paper: DualGAN: Unsupervised Dual Learning for Image-to-Image Translation
code: https://github.com/duxingren14/DualGAN
DualGAN的思想大致与CycleGAN一致,借鉴语言翻译里面的dual learning来实现非配对的两个图像域的转换。
损失函数
对于判别器:(应用时作者使用的损失形式参照了WGAN)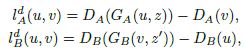
对于生成器:(其中的重建损失函数采用了L1 loss)
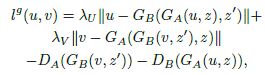
其中,$\lambda_U$ 与 $\lambda_V$ 是权重系数,根据应用的不同一般选择在[100, 1000]的范围内。
- 对于判别器,本文使用了PatchGAN,即判别器一次只对一个patch做判别,然后平均整幅图的结果作为预测值。使用PatchGAN在于捕捉局部的高频信息,因为低频信息已由重建误差加以保证。
- 训练过程是判别器更新 $n_{critic}$ 次后再更新生成器一次,采用RMSProp优化(因为基于momentum的Adam偶尔会导致训练不稳定),采用WGAN的处理方法。
 一个例子,将中国画转化为油画:
一个例子,将中国画转化为油画: