Abstract: 机器学习基石(林轩田)第五讲,训练与测试(Training versus Testing)
前期回顾
学习可以归结为以下两个问题:- 是否能够保证 ${E}_{out}(g) \approx {E}_{in}(g)$ ?
- 是否能够保证 ${E}_{in}(g)$ 足够小 ?
训练与测试对应的阶段如下:
$$
{E}_{out}(g) \underbrace{\approx}_{test} {E}_{in}(g) \underbrace{\approx}_{train} 0
$$
前面已知的结论是:
$$
\mathbb{P}[|{E}_{in}(g)-{E}_{out}(g)|>\epsilon] \leq 2·M·exp(-2{\epsilon}^{2}N)
$$
Trade-off on M- small M:
可以满足学习的第一个条件,不满足第二个条件(假设空间太小,选择太少) - large M:
可以满足学习的第二个条件,不满足第一个条件(假设空间太大,很差的假设变多,可能选到很差的假设)
因此,选择合适的M值 ${m}_{\mathcal{H}}$ 以达到折中的效果很重要的。
二维平面上的二分类直线情形的有效数量

union bound等号成立的条件是所有的 ${\mathcal{B}}_{m}$ 不重叠,实际很多情况下会有重叠部分,所以说按照原来的计算,union bound是被overestimated。
按照类别将假设空间划分为不重叠的区域,得到的有效假设的数量相比原来的union bound将减小。对于使用直线对二维平面上的点进行二分类的例子:
假设的有效数量
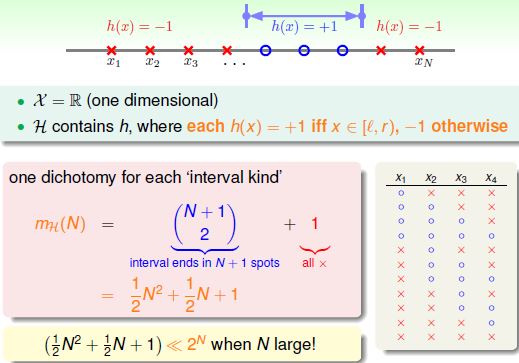
Dichotomy代表一种二分类的形式,使用dichotomy来描述直线的假设空间,能够得到假设数量最小的假设空间。那么相应的数量就从无穷多变成以 $2^N$ 为上限。
通过引入增长函数(growth function),代表所有情形下可能的最大的假设空间数量,从而排除了假设空间数量对于问题具体情形的依赖(比如平面上三点共线和不共线时对应的二分情形)。
(1) Growth Function for Positive Rays
(2) Growth Function for Positive Intervals
(3) Growth Function for Convex Sets
每一种二分都能通过凸集实现,因此可以称这N个输入被凸集假设打散。
转折点(Break Point)

要研究2D或者更普遍的perceptron的 ${m}_{\mathcal{H}}(N)$ 是否为多项式形式,需要先引入break point。
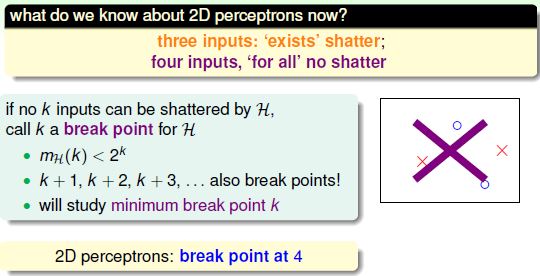
通过下图的归纳,似乎可以得到growth function与break point的关系呈多项式形态?疑问待后面解开。
